A content based recommender system works with user provided data to generate recommendations for the user. Recommender systems can be used to personalize information for a user and are commonly used to recommend movies, books, restaurants, and other products and services.
Using the Marijuana Recommendation System below or at the link here, we are going to use user selected effects and flavors to recommend five marijuana strains from a list of over 2,300 marijuana strains. In our case, the product is marijuana and the features are a list of effects and flavors.
A Word About the Code
All the code, data and associated files for the project can be accessed at my GitHub. The README file provides details of the repo directory and files.
The TF-IDF Model Using k-NN
TF-IDF refers to Term Frequency-Inverse Document Frequency. TF is simply the frequency a word appears in a document. IDF is the inverse of the document frequency in the whole corpus of documents. The idea behind the TF-IDF is to dampen the effect of high-frequency words in determing the importance of an item (document).
k-NN refers to K Nearest Neighbor and is a simple algorithm that, in our case, classifies data based on a similarity measure. In other words, it selects the “nearest” matches for our user input.
Let’s step through an example using the tf_knn.ipynb notebook. The basic steps are:
- Load, Clean and Wrangle the Data
- Tokenize and Vectorize the Features
- Create the Document-Term Matrix(DTM)
- Fit a Nearest Neighbors Model to the DTM
- Obtain the Recommendations from the Model
- Pickle the DTM and Vectorizer
Load, Clean and Wrangle the Data
The marijuana strains data came from the Cannabis Strains Marijuana Dataset from LiamLarsen in Kaggle. The data is loaded into a dataframe, the strains with nans are dropped (a small number <70), and the Effects and Flavor features combined into a Criteria feature.
df = pd.read_csv("https://raw.githubusercontent.com/JimKing100/strains-live/master/data/cannabis.csv")
df = df.dropna()
df = df.reset_index(drop=True)
df['Criteria'] = df['Effects'] + ',' + df['Flavor']
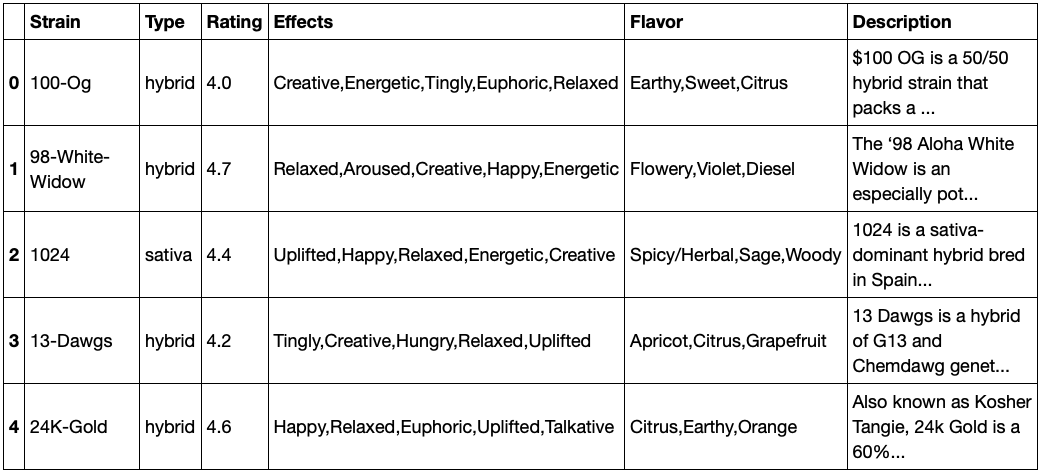
Tokenize and Vectorize the Features
The Effects and Flavor features were very clean, consisting of 16 unique effects and 50 unique flavors. We used the default tokenizer in the TfidVectorizer to tokenize the features, but if we wanted to extract features from a large text description, we would likely use a custom tokenizer. We then instantiate the vectorizer.
tf = TfidfVectorizer(stop_words='english')
Create the Document-Term Matrix
The features (Criteria) are then vectorized (fit/transformed) into a document-term matrix (dtm). The dtm is a matrix with each feature in a column and a “count” in each row. The count is the tf-idf value. The image below shows the vectorized matrix.
dtm = tf.fit_transform(df['Criteria'].values.astype('U'))
dtm = pd.DataFrame(dtm.todense(), columns=tf.get_feature_names())
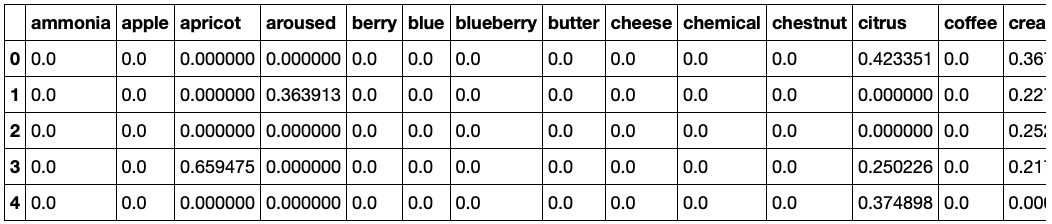
Fit a Nearest Neighbors Model
A Nearest Neighbors model is then instantiated and the dtm is fit on the model. This is our recommendation model used to select the top five recommendations.
nn = NearestNeighbors(n_neighbors=5, algorithm='ball_tree')
nn.fit(dtm)
Obtain the Recommendations
The ideal_strain test data variable represents the 8 features desired by a user. The first five features are effects and the last three features are flavors. The variable is then vectorized and run through the model. The results are returned in a tuple of arrays. In order to obtain the values, the 2nd tuple is accessed, then the 1st array then the 1st value - results[1][0][0]. In this case it returns the index of 0. The value of ‘Strain’ is ‘100-Og’ and the ‘Criteria’ matches the user features exactly. The 2nd example is index 1972 which has a value of ‘Sunburn’ for strain and matches 6 of the 8 features. The recommendations match the users features very well!
ideal_strain = ['Creative,Energetic,Tingly,Euphoric,Relaxed,Earthy,Sweet,Citrus']
new = tf.transform(ideal_strain)
results = nn.kneighbors(new.todense())
df['Strain'][results[1][0][0]]
#'100-Og'
df['Criteria'][results[1][0][0]]
#'Creative,Energetic,Tingly,Euphoric,Relaxed,Earthy,Sweet,Citrus'
df['Strain'][results[1][0][1]]
#'Sunburn'
df['Criteria'][results[1][0][1]]
#'Creative,Euphoric,Uplifted,Happy,Energetic,Citrus,Earthy,Sweet'
Pickling
Finally the dtm and vecotizer are pickled for use in the Dash app.
pickle.dump(dtm, open('/content/dtm.pkl', 'wb'))
pickle.dump(tf, open('/content/tf.pkl', 'wb'))
The Dash App
As this article is focused on the creation of a content-based recommendation system, the details of the Dash app will not be covered. For details on creating a Dash app see my article How to Create an Interactive Dash Web Application.
Marijuana Data Source: Cannabis Strains Marijuana Dataset from LiamLarsen in Kaggle